Data-driven marketing has become a fundamental part of running businesses. This is why businesses are increasingly collecting data from consumer interactions and engagements. However, dirty data can do more harm than good.
Before we dig deep into why dirty data is something you want to steer clear of, a quick reminder:
We want to emphasize the significance of GDPR compliance to our readers. Several businesses have faced legal issues because of improper setup. Hence, we advise you to hire professional GDPR consultants such as Teamwork IMS to ensure that your compliance is 100% accurate.
Psst, did you know that SyncApps offers unique insights into your customers’ behavior AND it’s 100% GDPR and CAN-SPAM compliant? Click here to automate your Salesforce data today.
What Do You Use Data for?
Typically, data is analyzed to help businesses predict future or emerging consumer behavior. This process involves understanding the data collected and knowing how to organize it, analyze it, and apply it to improve marketing efforts.
Most marketers use the same data to improve and personalize their customer experience. Seventy-eight percent of organizations say that the data they collect helps them increase customer acquisitions and lead conversions.
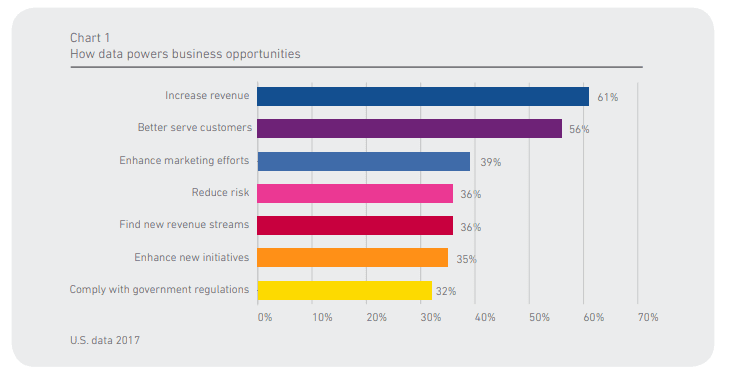
Data-driven marketing has, therefore, become a crucial strategy for marketers who want to succeed in the current hypercompetitive economy. Ninety-five percent of organizations are using data to power their business opportunities.
However, this can only occur if your data is clean. Dirty data can negatively affect your bottom line. Eighty-nine percent of business executives say that inaccurate data affects their ability to provide great customer experiences.
When your company is swimming in dirty data, the sales and marketing teams cannot make well-informed and accurate, data-driven decisions. On average, organizations believe that 25 percent of their data is inaccurate, a factor that impacts on the bottom line.
Dirty data can be costly in the long run. It can eventually lead to lower productivity, unnecessary spending, and unreliable decision-making.
In this article, we will look at:
-
- How Much Can Dirty Data Cost Your Business
-
- How Do You Process Data from Dirty to Clean?
-
- Benefits of Having Quality Data
- Getting Rid of Dirty Data and Saving on Cost
What Is Dirty Data?
Dirty data is simply data that contains errors, is incomplete, or duplicated needlessly An example of dirty data is a misspelled email address or data stored in a format that’s inaccessible to your current tech stack.
Data can be dirtied due to factors like:
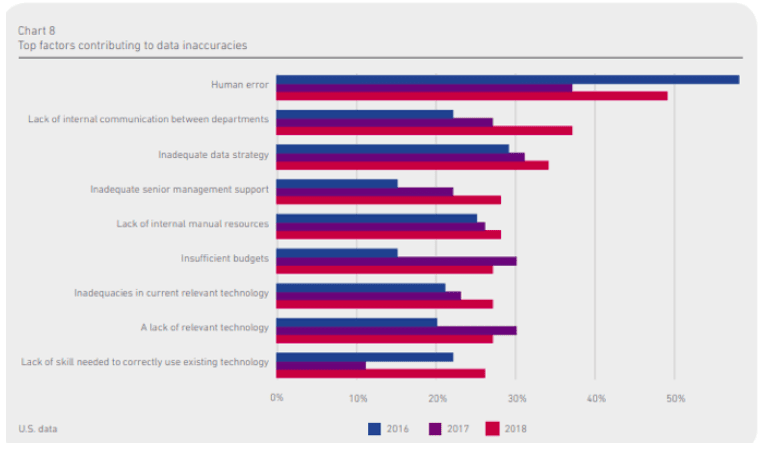
Human error: It is one of the major data health problems. Many of the processes require manual input of data, and this can cause errors. The errors get worse if those inputting data have no technical knowledge. Knowledge of what value to input in what field will lead to useful information. Such information is then passed on to the rest of the organization.
Incomplete data: This is data that’s been left blank. Without it, some of the functions in the marketing and sales department will not work efficiently.
Duplicate data: Duplicating customer records or products leads to high costs for the company. An excess in inventory, for example, can hamper procurement decisions.
Incorrect data: This kind of data occurs when, during input, the creation of values outside of a valid range happens. It could also be due to variations in spelling, typos, formatting problems, and transpositions. Incorrect data results in the wrong interpretation of data.
Inaccurate data: Accurate data is not always equivalent to correct data. Inaccuracies within data can lead to unwanted disruptions in business operations. One common example is when customers must provide all the necessary information to complete online forms. Whether intentional or accidental, inputting inaccurate data can put your business at a disadvantage.
Inconsistent data: This happens when the same values of data are stored in different locations, causing redundancies and inconsistencies. For example, an organization has company information in different non-synced systems or apps.
Storage failure: Hardware failure can also cause data corruption or loss. The loss and corruption can lead to disruption and, ultimately, loss of revenue. For instance, data loss leads to failure to deliver services or products to customers.
Old data: Some data expires after some time. For example, when a customer changes their phone number or moves to a new location.
Dirty data also occurs when organizations link data across sets. If there is no unique identifier for the data, linking them creates problems. These problems include repeated entries combined as a result of minor errors.
Data can sometimes be incorrectly combined, particularly when data about two customers with the same name is mixed up. This issue is often caused by outdated technology or when multiple databases are merged to consolidate data. Similar problems can arise when data is condensed to make it more manageable.
Worried that dirty data can impact your bottom line? Make sure it’s clean the moment it enters your organization. Integrate Salesforce with your other mission-critical solutions to avoid human and manual migration errors. Start here!
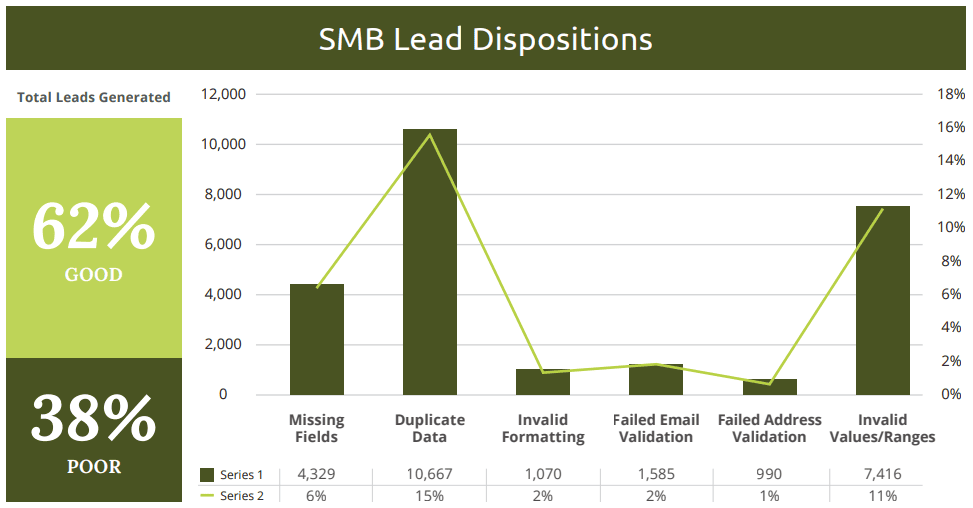
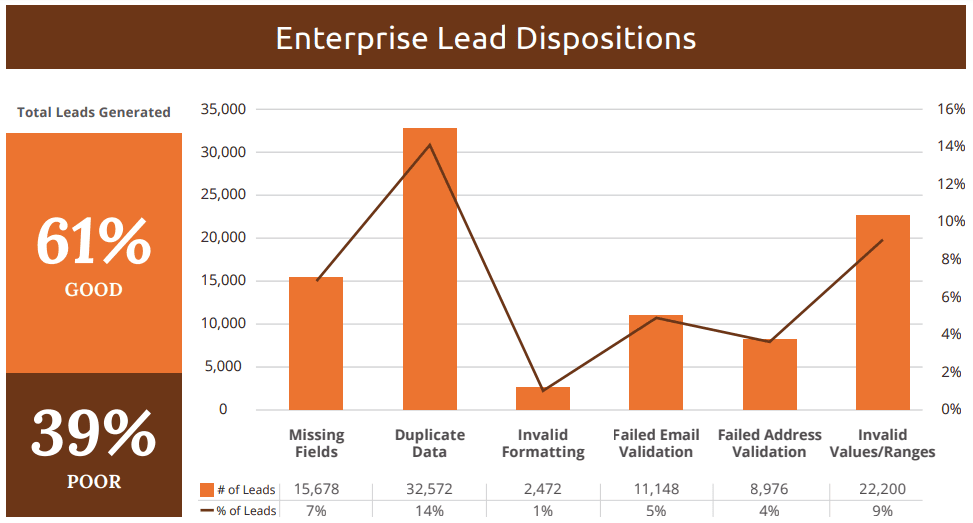
In a study conducted by Integrate, small and medium businesses were averaging 40 percent poor quality generated leads. Other issues included duplicate data, missing fields, invalid figures or ranges, failed address verification, and failed email verification.
When they carried out the same research on enterprise businesses, the results were not too different.
It’s sad to see businesses relying on poor data without giving this valuable resource the serious attention it requires to succeed in data-driven marketing.
If data is inconsistent across departments, the business cannot leverage it for intelligent insights. For example, if you need to store purchase orders and product sales information in the same database.
This data needs to be checked regularly for quality. Otherwise, it may be years before it is identified and corrected.
Sometimes, data problems are not noticed because everyday processes are unaffected. As such, it’s impossible to notice the error until the company requires the data for analytics. These kinds of problems affect revenue directly.
Worried that dirty data can impact your bottom line? Make sure it’s clean the moment it enters your organization. Integrate Salesforce with your other mission-critical solutions to avoid human and manual migration errors. Start here!
How Much Can Dirty Data Cost Your Business?
The result of poor-quality data is an increased cost per customer, fewer conversions, reduced revenue, and reduced profits. If these issues go unnoticed, numerous losses in resources and productivity will occur.
In a report by Experian Marketing, the effect on revenue comes primarily from:
- Lost productivity
- Wasted communications and marketing spend
- Wasted resources due to wrong decisions
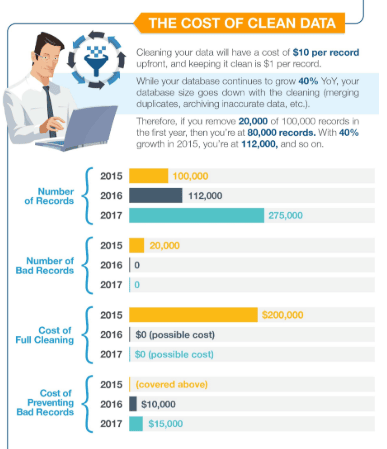
Consider that, on average, corporate data grows at a yearly rate of 40 percent. Twenty percent of that data is outright dirty. According to data scientists, it takes $1 to verify records, $10 to clean them, and $100 if you do nothing.
It’s the 1-10-100 rule. Fail to clean it, and the company spends $100 per dirty record. The infographic below calculates the huge cost bad data would cost your company.
With dirty data:
- Your salespeople will waste a lot of time using the wrong data to chase leads
- Your salespeople will have a hard time tracing the lead source
- Data scientists spend lots of valuable time cleaning data
- Your IT department will spend more time lining systems that are not connected
- Your team will make the wrong decisions. If they do not trust the data, they will end up doing a lot of guesswork
- Your financial report will lead to a bad investment, leading to reputational consequences and loss of revenues
- Duplicated information will lead to reputation damage. For example, by not cleaning data, two sales reps end up calling the same customer by accident.
- Wrong updates to email preferences will lead to wrong records that do not honor a customer’s opt-out preference. You could also be emailing the wrong addresses. Such mistakes will strain your relationships with customers, which will affect retention.
- Your accounts can be adversely affected. This can happen if you fail to update old data. For example, if you acquired another company and failed to update data, your records will not be accurate.
- Product/service delivery people will spend more time making corrections to flawed customer orders
- Wasted media spend as the money used for ads is lost through failed email verification and wrong addresses
- Your company will incur unnecessary costs on marketing automation and CRM for duplicate records
- Your company risks losing clients due to poor quality service and customer experience
- You waste a lot of precious space in data storage as the server gets filled up with useless data
- Incorrect segmentation leading to poor personalization
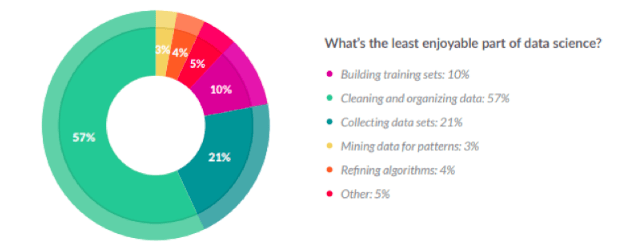
According to studies, knowledge workers waste 50 percent of their valuable time looking for dirty data, identifying it, and making corrections. They also spend valuable time ensuring that the data can be trusted. Research by Crowd Flower also found that 60 percent of data scientist’s time is spent cleaning and organizing data.
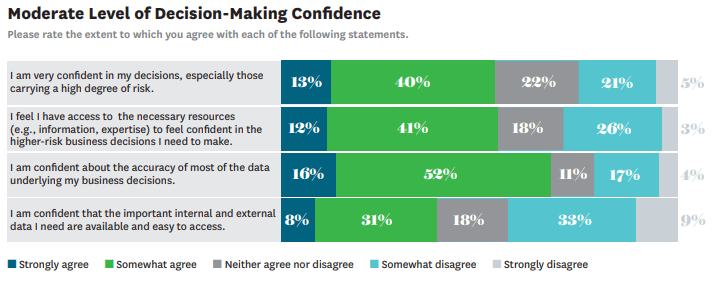
Organizations need to work with clean data. Research by Harvard Business Review found that only 16 percent of executives are confident in the accuracy of most of the data they use when making decisions.
Only eight percent were confident in the availability of internal and external data needed to make decisions. If the executives can’t rely on the data collected to make decisions, then changes to improve accuracy and reliability should happen.
How Do You Process Data from Dirty to Clean?

Before discussing how to clean your data, it’s important to note that small mistakes made during data collection can eventually result in big consequences in the long run.
Processing your data from dirty to clean isn’t exactly pleasant, but it’s not optional, either. It will take time to clean it up. To avoid such costly inconveniences, you’ll be better off putting in place a proper data-collection system.
Although the organizational structure of different companies determines how they handle data, everyone, including those in marketing, finance, operations, and customers, owns and needs the data.
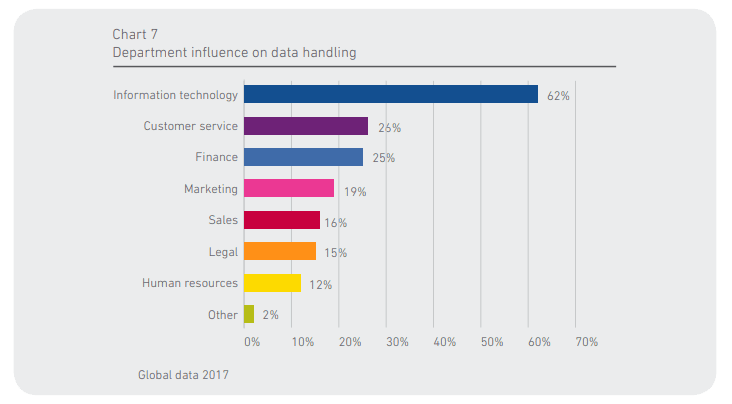
Data ownership is one of the data-related challenges facing organizations. Who owns the data? In a 2017 study by Experian, the IT department had the most significant influence on data handling in 62 percent of organizations.
Business owners did not take an active role in data handling, which they needed for decision-making and initiatives. Ninety-five percent of businesses were making data requests from the IT department, and over 70 percent of them had to wait a day or even longer to receive the data they had requested.
Today’s fast-paced environment and the shift to cloud-based storage have changed all that, thankfully. More business owners now own the data. Business owners are even gaining expertise on how to handle and analyze data.
All these things make processing your data from dirty to clean more bearable.
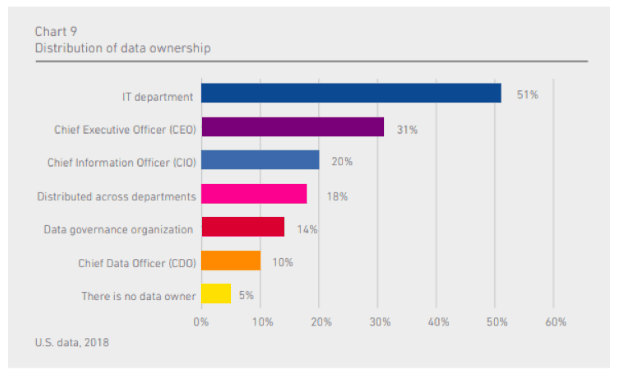
Although the IT department still owns data in 51 percent of organizations, half of the organizations no longer believe the IT department should own the data.
Chief executive officers now own data in a third of the organizations. The CEO owns the business strategy, and the data responsibility is shifting to them, too. This means they are also responsible for protecting the data from emerging cyber threats and ensuring they adhere to all regulations and ethics.
Since most departments in your organization use data, coordination must happen so that it remains clean. This means that your company must make data quality everyone’s responsibility. Make everyone responsible for it and align this with the goals your company aims to achieve. This will go a long way in helping to improve data quality.
All teams should collaborate to ensure data accuracy. Integrate databases to increase conversion rates. Communication and collaboration between the marketing, sales, and all other departments in the organization will help demolish silos.
It will ensure data accuracy and not infringe on the working styles of employees. Train employees on the correct processes and enforce a strong law on data quality.
Now that everyone is responsible for data quality as the company tries to achieve its goals, it’s time to clean existing data.
How Do You Clean Dirty Data?
1. Analyze Existing Data
The first step towards a clean database is analyzing the data. The process will tell you which data requires immediate action and which one they can tackle moderately.
To understand the challenges your company is facing, you will need to access missing fields, significant gaps, wrong information, inaccurate (phone) numbers, and wrong formats. The information garnered will show the dirty data locations.
When analyzing your data, the anomalies and patterns you discover can provide valuable insights into how it was collected. Consider implementing systems that can detect and address these anomalies to improve the quality of your data. You may also want to explore the services of SaaS companies that offer data clean-up and pattern recognition to streamline this process. Or if you’re an avid Mac user explore how to free up RAM on Mac and eliminate unnecessary data to optimize your device’s performance.
However, learning how to handle these problems internally will go a long way in ensuring that such situations do not arise in the future. Your organization needs data-related goals and a well-thought-out roadmap on how to use the data to reach targets.
Audit all your internal systems and platforms, starting from where you collect your information. This includes webinar registration forms, survey forms, and download forms. Consider which field(s) your team should remove and which ones should remain.
One thing you should note is that when you ask for personal information too early in the buying process, potential customers will most likely lie to remain anonymous. The same will happen if the forms require too much input.
People generally don’t like answering too many questions. Now, this is where dirty data thrives.
It is also worth noting that not all anomalies may be bad. Use your human intuition to take note of patterns that may provide new insights.
For example, if you run a gym and discover a huge number of what appears to be inaccurate information, don’t rush to discard it as “dirty data.” It could be a gold mine.
So, if you are targeting the working-class population in your location and you notice that your records show that a huge number of teenagers have been frequenting your establishment on weekends, this should tell you something.
Such data tells you that there’s a potential demographic that is untapped. It is now entirely up to you to exploit this discovery and make it work for your business.
Before you get rid of all the data, ensure you’ve analyzed it extensively. Try to find patterns that can provide you with useful information or opportunities you may not have considered before.
2. Standardize Data Collection Rules and Establish Constraints to Prevent Dirty Data
Having standardization rules will ensure the quality of your data. The rules should apply to all systems. Start by standardizing input fields in the CRM and other systems you use to collect customer data:
- Consistently represent numbers, nominal values, and monetary values
- Avoid case-sensitive inputs unless necessary
- Normalize salutations, including Mrs. and Ms.
- Normalize spelling to one standard dictionary
- Convert abbreviations to long-form or long-form to abbreviations
- Have all customer records updated after every interaction
Develop constraints to protect the company from dirty data. Constraints ensure consistency of data, minimizing dirty data. For example:
- Make some fields mandatory
- Have range constraints that prevent nonsensical values that go below or above a certain threshold
- Mandate certain data types when inputting values
3. Avoid Complacency with Your Data
Once done with cleaning and the data shows some improvement, do not get complacent. Continually improve your processes to avoid contaminating your data. Keep ensuring that your data collection and verification processes are always updated.
Find out what data you cannot access and why. Are you looking for certain information but can’t access the data?
Need more reasons to sign up for our AI-powered customer mind-reading solution? How about the fact that it’s 100% FREE and not as in a free trial -- you can use basic integration features for as long as you need.
Upon finding the dirty data, how fast can you act on it, and what damage will it have wrecked on the organization? Keep your data collection system and the employees on their toes all the time.
Update data regularly. According to research, in a year:
- 35 percent of emails change
- 43 percent of phone numbers change
- 20 percent of postal addresses change
- 21 percent of CEOs change
- 30 percent of people change jobs
- 65 percent of people change job titles or functions
Combine these statistics with the fact that B2B data decays at a rate of 70.3 percent in one year.
If you don’t constantly update your information, your company is most likely using the wrong information when contacting customers and sending the wrong messages.
4. Automate Your Data Cleaning Process
According to a report by Crowd Flower, data scientists love their job. However, 60 percent say they prefer to avoid work that takes up most of their time (cleaning and organizing).
You can see that the tasks they spend most of their time doing are the ones they don’t enjoy. Data scientists would rather be doing creative and exciting jobs than process data from dirty to clean.
Manually cleaning data is uneconomical and labor-intensive. You must invest in a system that automatically cleans, enriches, appends, and analyzes your data.
As we have seen, human error is the leading cause of dirty data. One error can lead to huge losses in terms of revenue. Using automated systems ensures that you sift through the data collected using algorithms that detect any anomalies and errors.
Automation also scrubs off duplicate records from your database. For example, your company will have two records of a customer if they input a work email and a personal email.
Such data will prevent you from having a 360 view of the customer. Automated systems will merge the data and remove duplicate records, ensuring data quality.
Automating also helps you keep updated records of customers in real-time. Your sales team will no longer chase dead-end leads. This will help you maintain the trust of your customers.
Benefits of Having Quality Data
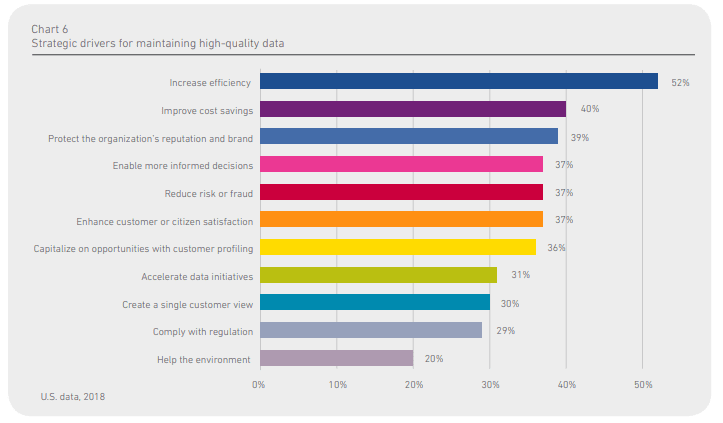
Developing a data strategy will ensure quality data, which is critical to achieving your business goals. Certain needs drive the strategies to maintain high-quality data, including
Increased Efficiency
- Saving on costs: Having high-quality data ensures that you don’t have to pay the price for cleaning data. You can note mistakes early on and make accurate data-informed decisions.
- Protecting the organization’s reputation: Bad data can ruin your reputation.
- Getting data confidence: Data ensures trust and an understanding of the information you have at your disposal. Your team will, in turn, have confidence in the insights provided by derived data.
Making Informed Decisions and Effective Marketing
- Scaling up while ensuring reliable and trustworthy data. With quality data, the company does not have to scale up through increasing human resources.
Improving Operational Efficiency
- Saving time: Data scientists no longer have to spend time backtracking or double-checking results. Automated processes will further ensure quality data and save you valuable time.
- Ensuring consistency in data: A strong data infrastructure ensures that data is consistent throughout the organization. Teams will work with the same sales figures, congruent reports, and harmonious data.
- Readiness and the ability to detect inconsistencies. If something goes wrong, you are ready to tackle it. This readiness minimizes the cost of errors since you can never have a completely flawless solution.
- Increasing productivity: Time saved means that your team can spend more time being creative and innovative.
- Complying with data regulations: Your data will be following set guidelines making it easy to comply with industry regulations.
- Ensuring customer satisfaction: Maintaining control of your data ensures that you handle customer data properly. You also have the right information and can personalize and improve experiences.
Conclusion: Get Rid of Dirty Data and Save Money
The world has increasingly become connected. This means that there’s a lot of data being collected and stored. Big data has huge responsibilities, and companies must ensure data quality and protection.
With quality data, your company can generate up to 70 percent more revenue. Sorting out your data can save you a lot of money. Clean data can also enhance the growth of your business.
Do not slow your organization down with dirty data. Integrate automation and modern techniques to minimize dirty data collection and storage. With clean data, your organization becomes responsive and agile. You also cut down on wasted time and improve the productivity of your employees.
Quality data helps you understand insights and stay in touch with customers. It enables you to market more effectively and grow loyalty from customers.
Ensure your data is always clean through consistent checks to gain customer trust and make knowledgeable business decisions.
How do you ensure your data is clean? We’d like to hear from you. Book a call with our experts now!